在垂直领域大模型训练中,人工标注成本高昂,合成数据又常陷入质量与专业性难以兼得的困境。
为此,上海AI实验室等提出GraphGen。
通过“知识图谱引导+双模型协同”机制,显著增强模型对垂域的理解能力。
同时,研究团队已经在OpenXLab部署了Web应用,上传你的文本块(如海事、海洋知识)、填写SliconCloud API Key,即可在线生成LLaMA-Factory、XTuner所需的训练数据。
️背景说明
垂域模型(如医疗、农业)训练中,获取QA(问答对)数据常常面临以下难题:
️量大。只是学习回复风格只需数百条,尚且能人工标注;用SFT(Supervised Fine-Tuning)给模型注入新知识,需要数十万的样本量,此时数据合成手段是刚需。
️专业背景。开源LLM在小众领域已经表现不错,但垂域应对的是真正的“硬骨头”。面对领域数据,普通人可能每个字都认识,但连在一起并不知道什么含义。比如,不借助工具,请试着读懂这句:

️质量把控。“LLM-RAG-打分”通常也被拿来合成 SFT 数据,但这条pipeline存留一些问题:
正确性。在LLM不具备领域知识时,直接给领域问答数据打分,容易陷入“先有鸡先有蛋”的难题
简单的关联度得分也不足以衡量数据质量,不仅没有回复长度、信息丰度等指标,更缺少语义层面的保证
️方案介绍
为了解决以上问题,上海AI Lab开源了GraphGen,一个在知识图谱引导下的合成数据生成框架,旨在知识密集型任务中生成问答
aspcms.cn 这是基于GraphGen和SiliconCloud Qwen2.5-7B-Instruct API实跑的 QA 样例:

GraphGen会使用到两个LLM,一个是合成模型,负责构建知识图谱、合成数据等;另一个是学生模型,用来识别它自己的知识盲点,方便针对性的选择数据。
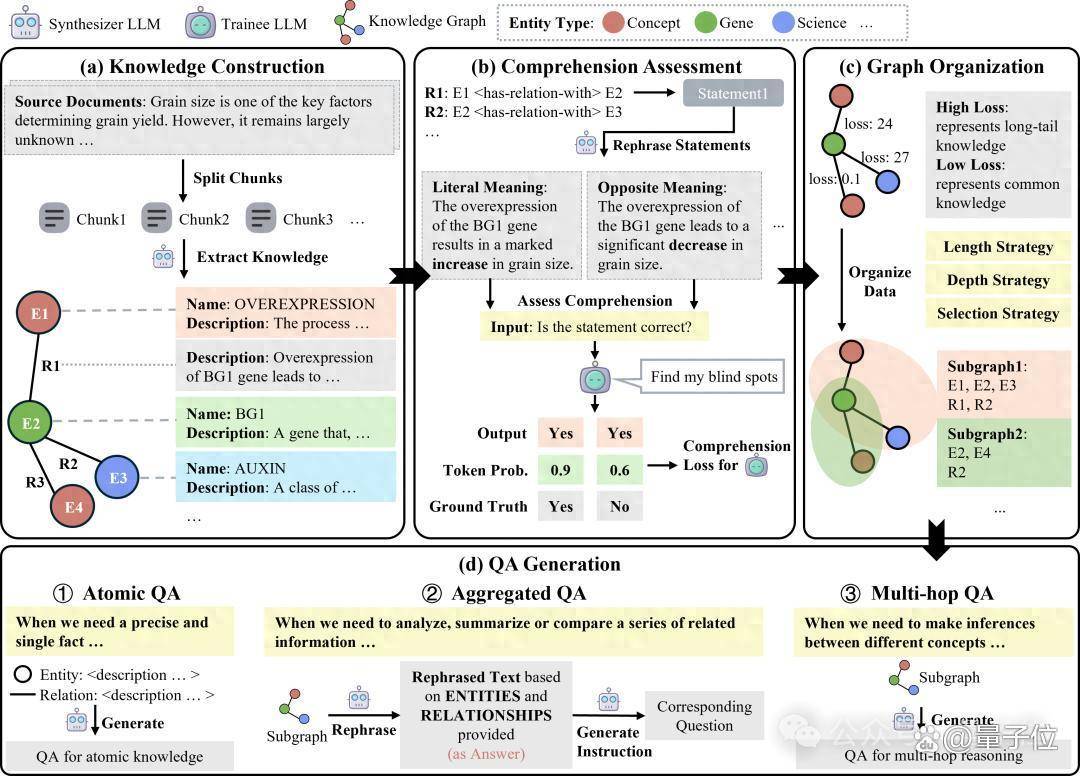
上图是GraphGen工作流:
首先输入一段原始文本,使用合成模型从源文本构建细粒度的知识图谱。
然后,利用预期校准误差(Expected Calibration Error, 简称 ECE)来识别学生模型的知识盲点,针对知识盲点优先生成针对高价值、长尾知识的问答对。
接着,GraphGen框架结合多跳邻域采样来捕捉复杂的关联信息,并采用风格控制生成技术来使生成的问答数据多样化。
最终得到一系列和原始文本相关的问答对。用户可以直接用这批数据在llama-factory或者xtuner这样的训练框架中进行SFT。
优秀的数据合成方法有很多,研究团队在论文中做了对比测试:
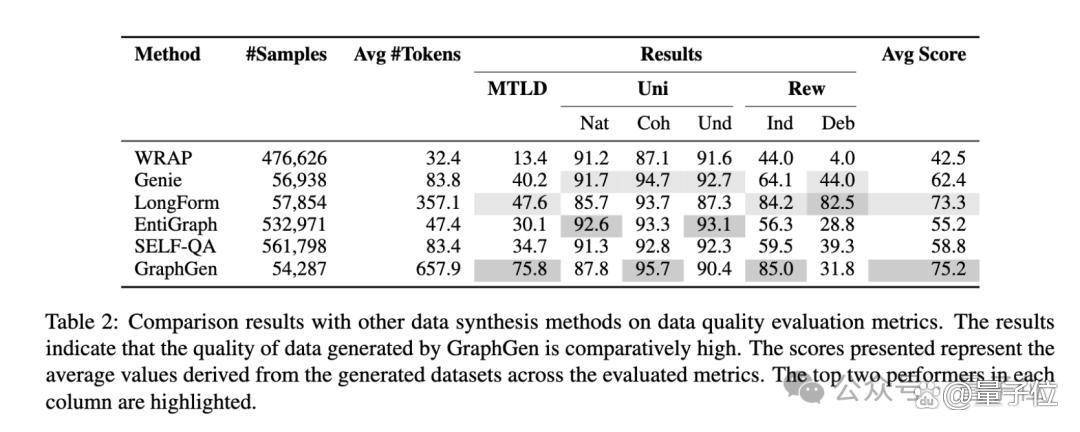
研究团队采用的是客观指标:
MTLD(Measure of Textual Lexical Diversity)通过计算文本中连续词串的平均长度来评估词汇的多样性
Uni(Unieval Score)是基于对话模型的自然度、一致度、可理解度评价指标
Rew(Reward Score)是BAAI和OpenAssistant开源的两个Reward Model计算的得分
由上图可见,GraphGen能给出相对较好的合成数据。
同时研究团队在开源数据集(SeedEval、PQArefEval、HotpotEval 分别对应农业、医学、通用)训练测试,结果表明GraphGen自动合成的数据能够降低Comprehension Loss(越低代表学生模型的知识盲点越少),增强模型对垂域的理解力。