电商平台上,商品数量庞大,图片管理难度极高。为全方位展示商品,每件服装需多视角、多色、多尺码的图片,这些图片不仅数量多,还包含商品编号、颜色、尺码、款式等关键信息。商品编号利于库存与销售管理,颜色、尺码和款式信息则辅助消费者选购。
利用图片区域识别重命名功能,可高效解决图片管理难题。该功能运用先进图像识别技术,能精准抓取图片特定区域文字。比如,通过算法分析,抓取商品编号数字、颜色词汇、尺码标识及款式术语,随后将这些信息组合成新文件名,像 “230516_白色_S_运动鞋.jpg”。这种方式极大提升了图片管理效率与准确性,便于商家快速查找、筛选和整理图片,为商品上架、库存管理及数据分析等工作筑牢基础。

如何识别图片/PDF区域内容对文件进行改名处理或将内容导出表格,在处理大量图片或PDF文件时,常常需要提取特定区域的文字内容,并根据这些内容对文件进行重命名或导出到表格中。以下是几种高效的方法,帮助你快速完成这些任务。
方法一:使用“咕嘎批量OCR识别图片PDF多区域内容重命名导出表格系统”️操作步骤:
️下载与安装
找到Timor君后,发消息:️图片识别重改名
️打开软件并选择处理模式
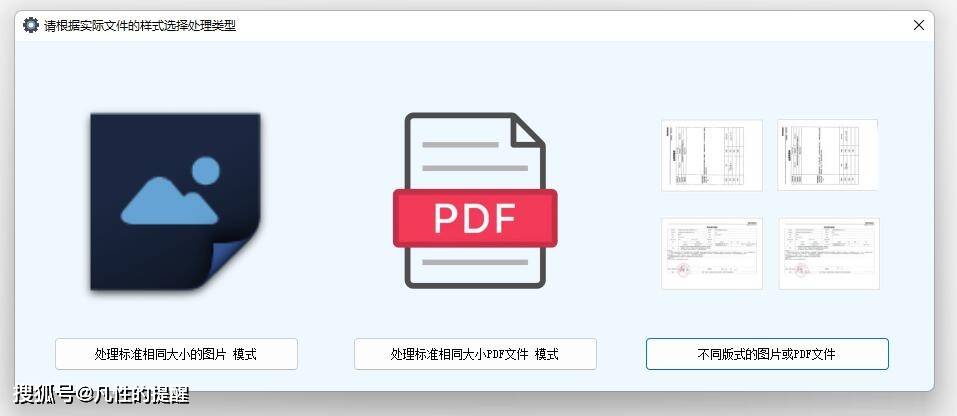
打开软件后,选择“图片处理”或“PDF处理”模式,根据文件类型选择合适的模式。
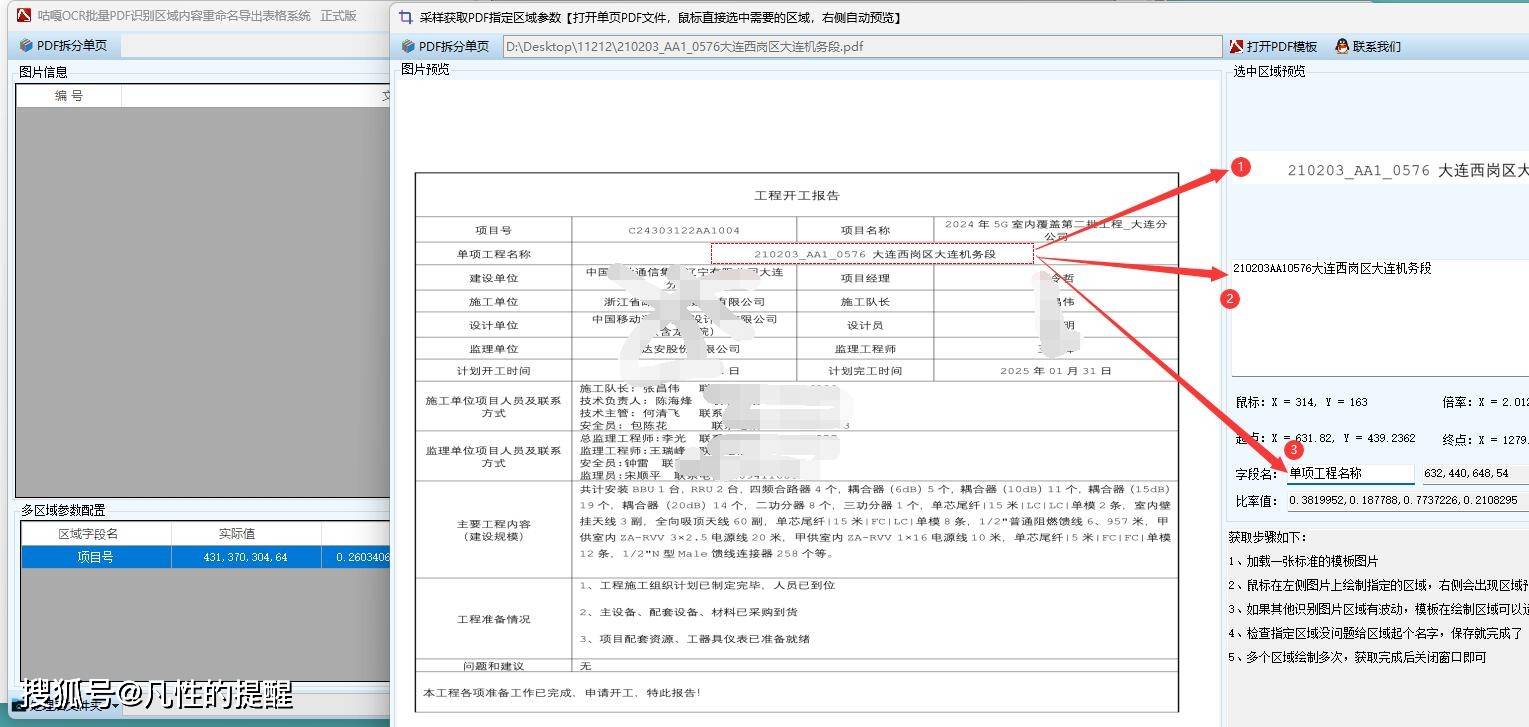
️设置识别区域
️批量处理文件
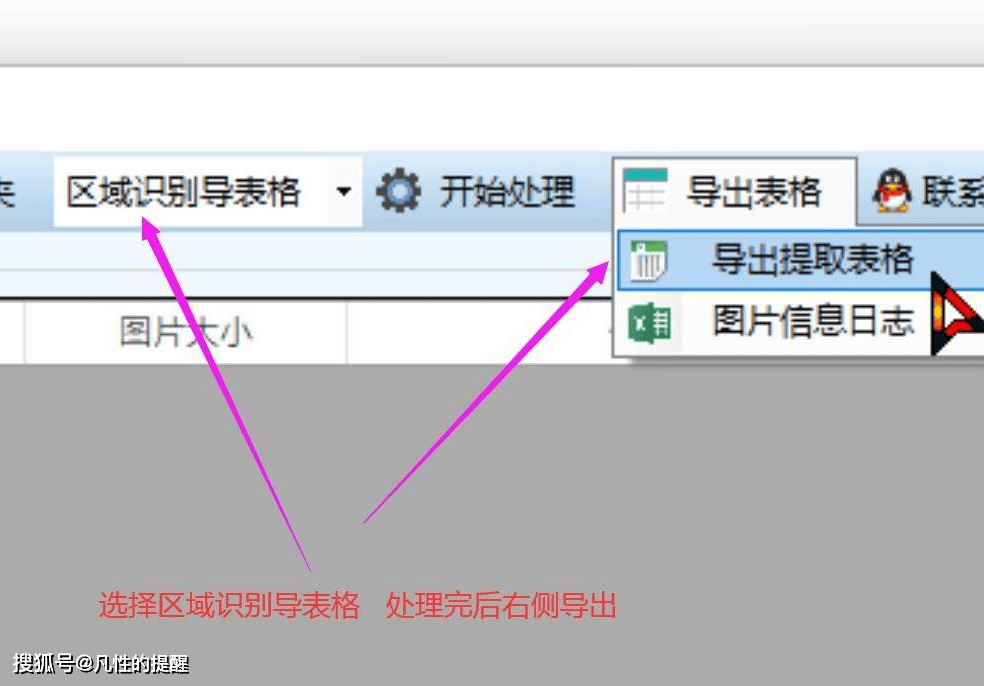
️开始处理
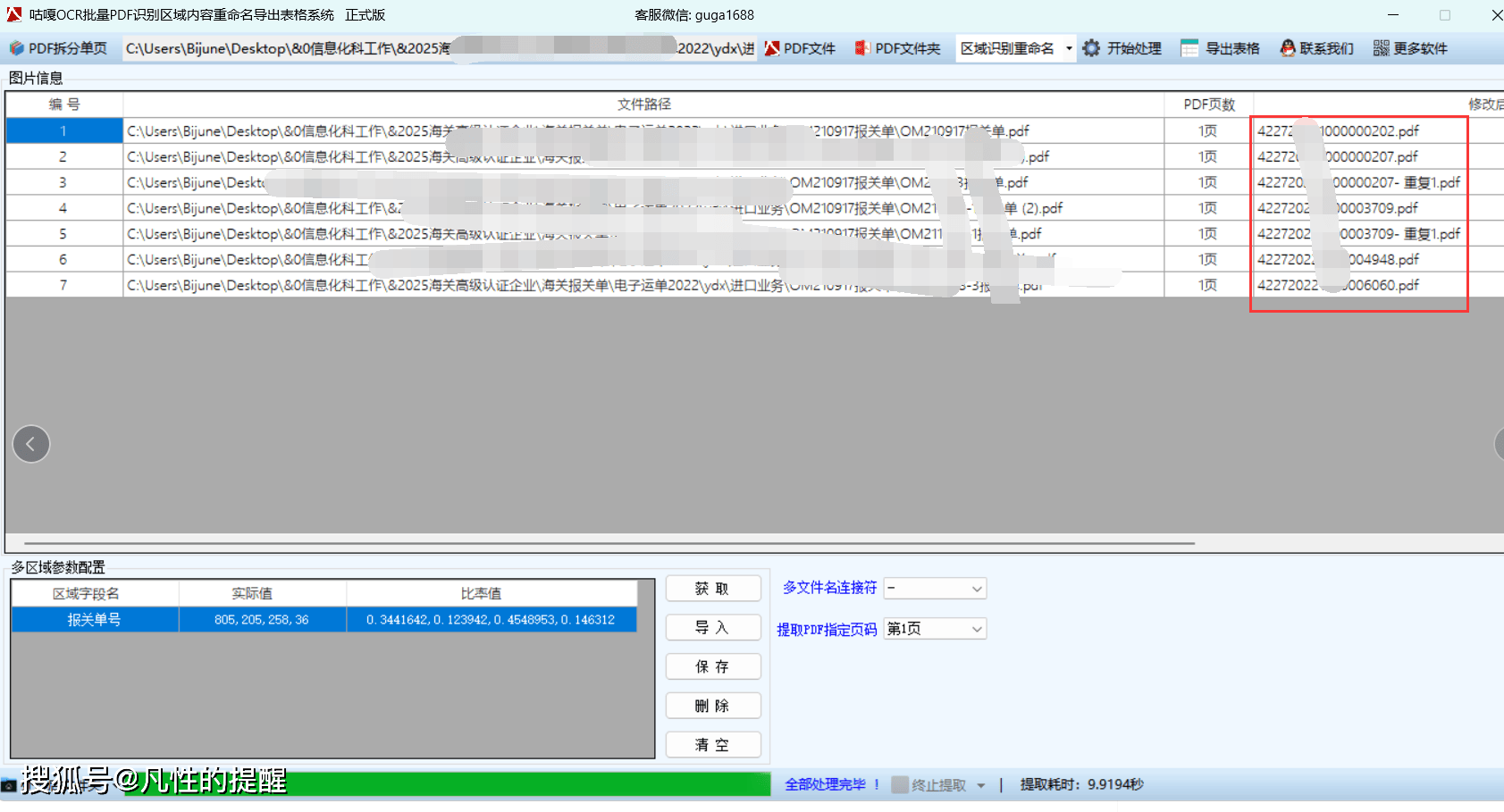
️查看结果:查看文件是否已根据识别内容重命名,或检查导出的Excel表格是否包含正确的识别内容。
方法二:使用Python脚本(基于PyMuPDF和Pandas)如果你熟悉编程,可以使用Python结合PyMuPDF和Pandas库来实现批量识别PDF区域内容并导出到Excel表格。

安装所需库
bash
pip install fitz pandas openpyxl
示例代码
Python
import os
import fitz # PyMuPDF
import pandas as pd
def extract_text_from_pdf(pdf_path, regions):
"""
从PDF文件中提取指定区域的文字内容
:param pdf_path: PDF文件路径
:param regions: 区域列表,每个区域是一个字典,包含页码、x1、y1、x2、y2
:return: 提取的文字内容列表
"""
doc = fitz.open(pdf_path)
extracted_text = []
for region in regions:
page_num = region['page']
x1, y1, x2, y2 = region['x1'], region['y1'], region['x2'], region['y2']
page = doc.load_page(page_num)
rect = fitz.Rect(x1, y1, x2, y2)
text = page.get_text("text", clip=rect)
extracted_text.append(text.strip())
doc.close()
return extracted_text
def process_pdfs(pdf_folder, output_excel, regions):
"""
处理指定文件夹中的所有PDF文件,并将提取的内容导出到Excel表格
:param pdf_folder: 包含PDF文件的文件夹路径
:param output_excel: 输出的Excel文件路径
:param regions: 区域列表
"""
pdf_files = [f for f in os.listdir(pdf_folder) if f.lower().endswith('.pdf')]
all_data = []
for pdf_file in pdf_files:
pdf_path = os.path.join(pdf_folder, pdf_file)
extracted_text = extract_text_from_pdf(pdf_path, regions)
all_data.append([pdf_file] + extracted_text)
columns = ['PDF文件名'] + [f"区域{i+1}" for i in range(len(regions))]
df = pd.DataFrame(all_data, columns=columns)
df.to_excel(output_excel, index=False)
print(f"提取完成,结果已保存到 {output_excel}")
if __name__ == "__main__":
pdf_folder = "path/to/your/pdf/folder" # 输入的PDF文件夹路径
output_excel = "output.xlsx" # 输出的Excel文件路径
regions = [
{'page': 0, 'x1': 100, 'y1': 200, 'x2': 300, 'y2': 400}, # 区域1
{'page': 0, 'x1': 350, 'y1': 200, 'x2': 550, 'y2': 400} # 区域2
]
process_pdfs(pdf_folder, output_excel, regions)
代码解释
️extract_text_from_pdf 函数:
️process_pdfs 函数:
️pandas库:
️应用场合
适合对 PDF 文件处理有较高要求,需要对 PDF 文件进行编辑、转换等多种操作,且对文件安全性和格式兼容性有保障需求的专业人士。常用于企业法务部门处理合同、金融机构处理财务报表等场景。

️详细步骤
咕嘎批量 OCR 识别系统专注批量处理多区域内容,功能集成度高;Adobe Acrobat Pro DC 在专业 PDF 处理方面表现出色,支持多种编辑操作;在线 OCR(如 OCR.Space)方便临时使用,无需安装但有一定限制;利用 Python 结合相关库可高度定制,适合批量自动化处理,但需要编程能力。实际应用中,可依据文件数量、处理需求、安全要求及自身技术水平,选择最契合的方法,高效完成图片和 PDF 区域内容识别、文件改名及表格导出任务。