大模型架构创新研究报告
2025-06-06
今天分享的是:大模型架构创新研究报告
报告共计:30页
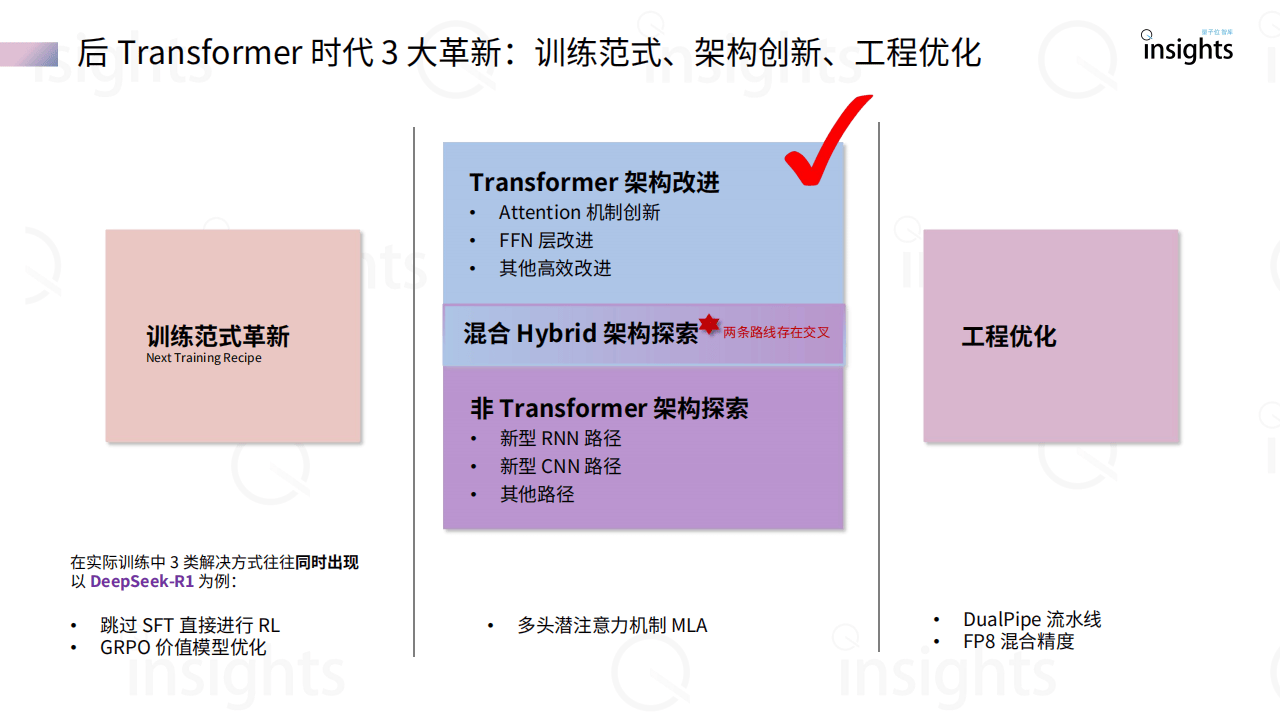
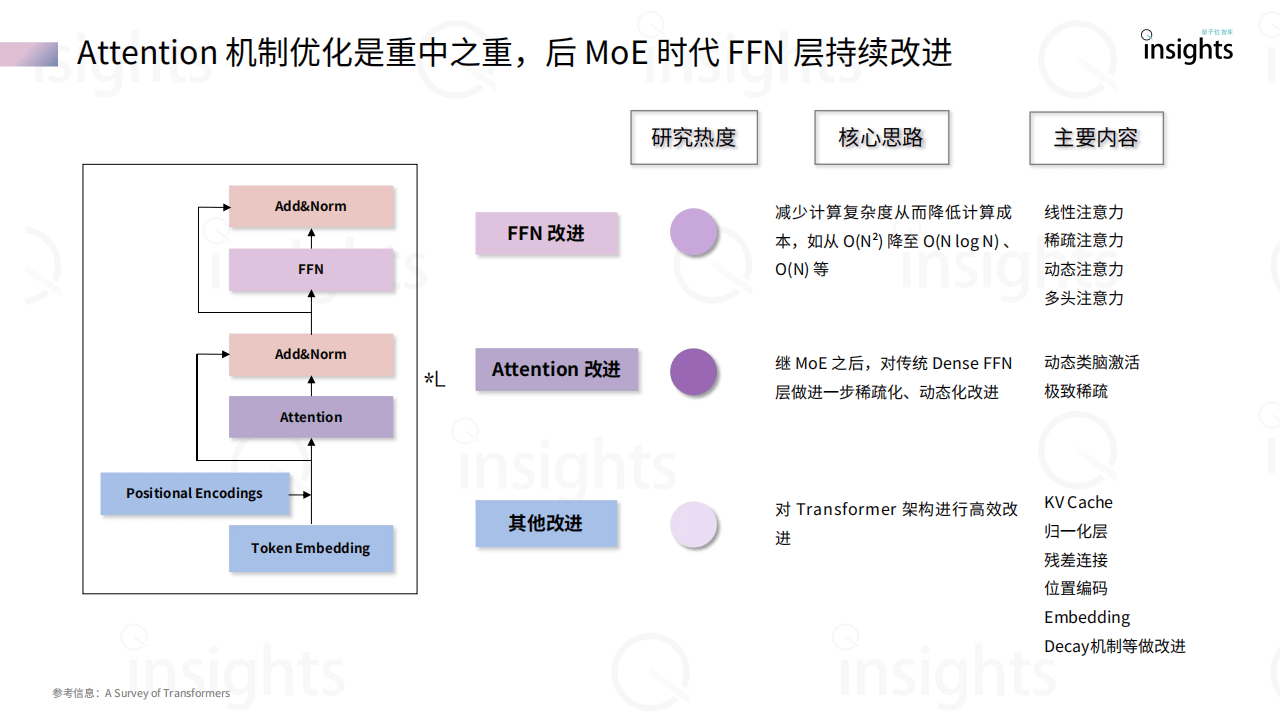
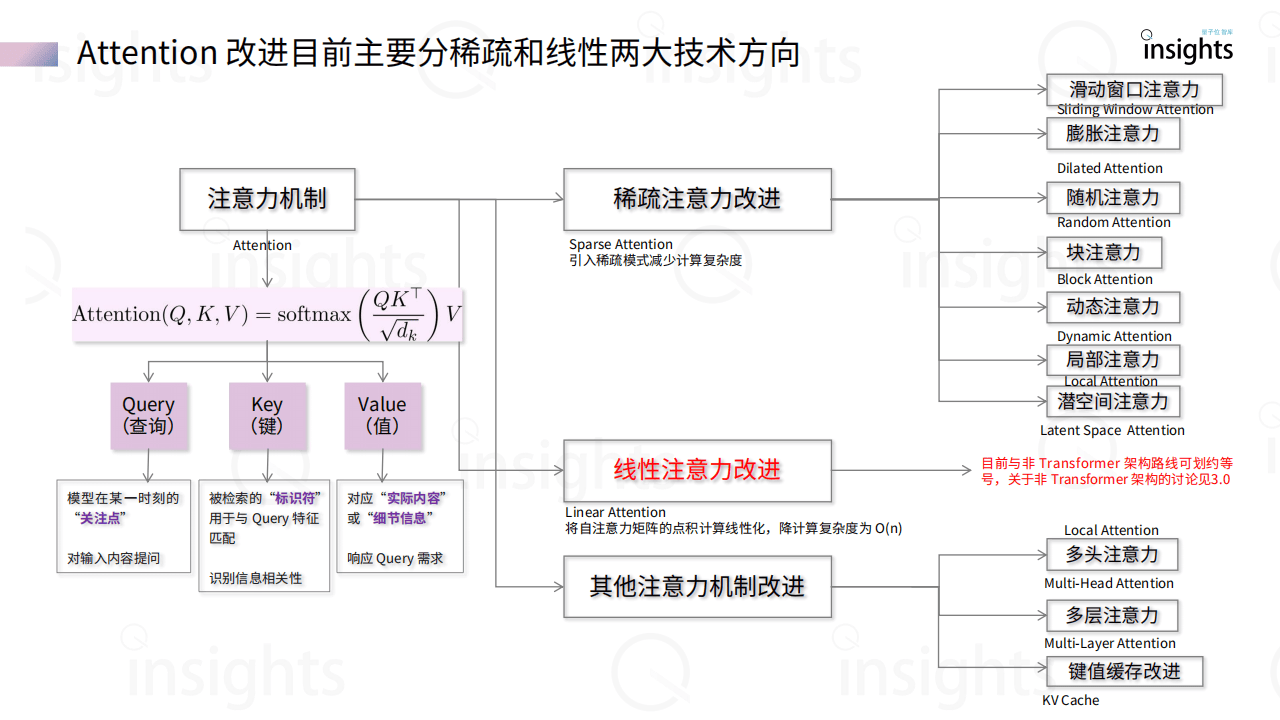
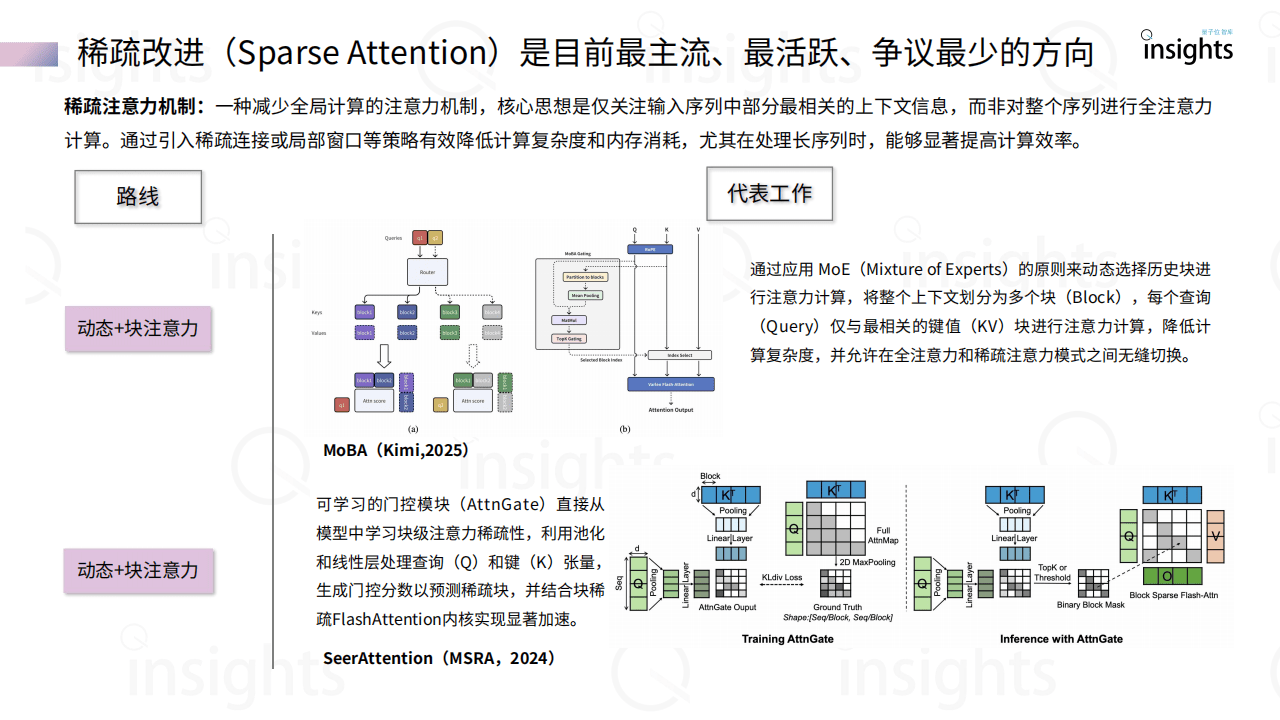
《大模型架构创新研究报告》聚焦大模型架构发展,指出自Transformer架构提出以来,AI行业对其路径依赖引发效率与存储等问题,当前架构创新主要沿Transformer改进和非Transformer探索两条路径展开。Transformer改进方面,围绕Attention机制(如稀疏、动态注意力)、FFN层优化(如MoE混合专家)及归一化层调整,旨在降低计算复杂度(如从O(N²)降至O(N log N)),提升长序列处理能力。非Transformer架构则涌现出新型RNN(如RWKV、Mamba)、CNN(如Hyena Hierarchy)及其他创新模型(如RetNet、TimeMixer),这些架构摆脱Attention依赖,在并行计算、推理效率和端侧部署上具优势,例如Mamba-2通过状态空间模型提升训练效率2-8倍,RWKV-7引入广义Delta Rule优化状态演化。报告提到,Transformer架构在追求性能天花板上仍占主导,但计算成本高昂;非Transformer架构侧重效率与智能密度压缩,适合端侧和小模型场景,两者正走向混合融合,Hybrid架构渐成趋势。当前行业处于传统Transformer范式见顶、新技术突破前夜,未来需平衡性能突破与效率优化,推动大模型在多模态、推理能力等方向演进,同时关注开源生态与工业级落地,如RWKV、Mamba等已进入实际应用阶段。
以下为报告节选内容